Pydantic Donating FastA2A to Datalayer

This article is cross-posted on the Pydantic blog: FastA2A is moving to Datalayer.

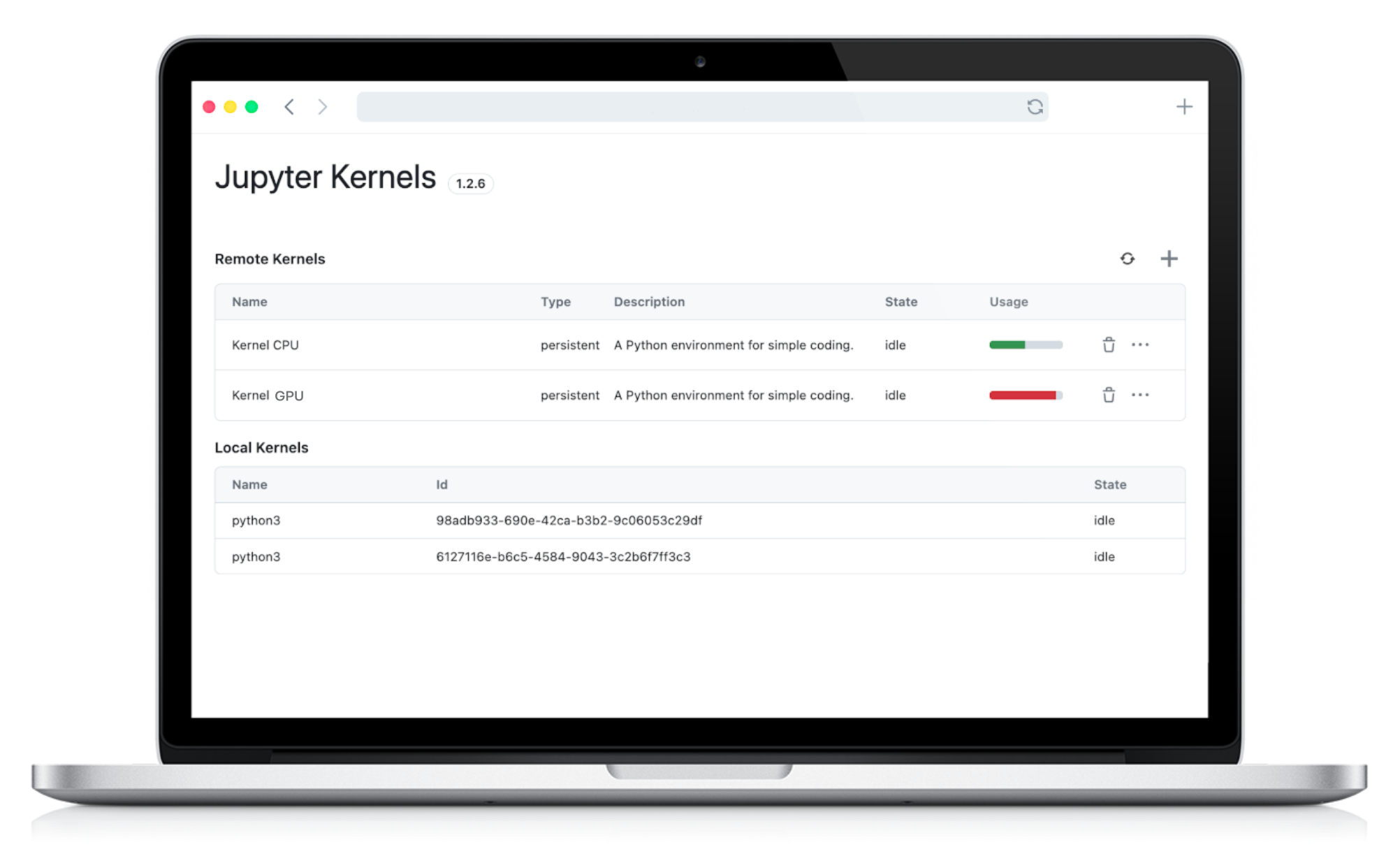
FastA2A Finds a New Home at Datalayer
The future of open agent-to-agent infrastructure is community-driven, and today we are excited to announce an important new chapter for FastA2A.
After a strong collaboration between Datalayer and Pydantic, the FastA2A repository will be donated by Pydantic to Datalayer, which will now maintain and evolve the project going forward.
This transition builds on an already successful partnership between Datalayer and Pydantic, including the recent addition of streaming support to FastA2A and earlier collaborations highlighted in the Pydantic + Datalayer case study.
The new repository location for FastA2A is github.com/datalayer/fasta2a.
Browse the code and updates on GitHub.