Jupyter Embed: Transform Any Website into an Interactive Computing Platform
· 7 min read

We're excited to announce Jupyter Embed, the simplest way to bring the full power of Jupyter to any website, blog, or documentation page.
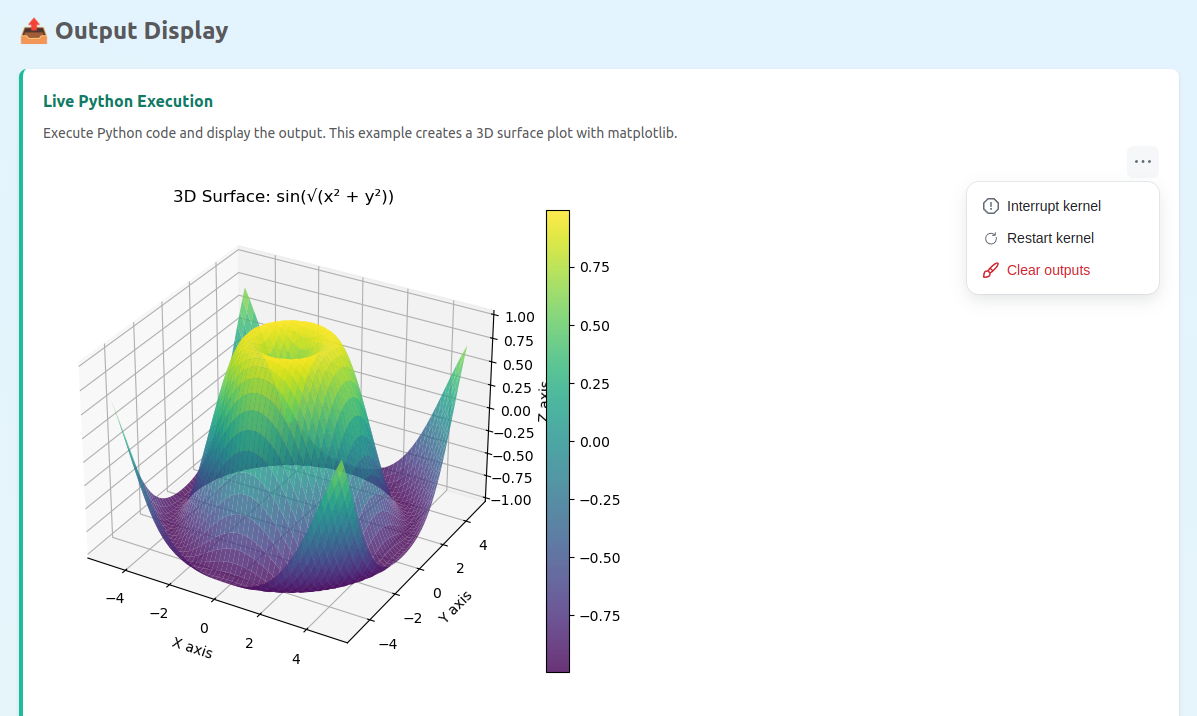
Want to see Jupyter Embed in action before copying any code?
The demo showcases all component types - code cells, notebooks, terminals, consoles, and viewers - running live in your browser. It works seamlessly across:
- ✅ Desktop browsers: Chrome, Firefox, Safari, Edge
- ✅ Mobile browsers: iOS Safari, Android Chrome
- ✅ Tablets: iPad, Android tablets
No installation required. Just open the link and start exploring interactive Jupyter components.