GPU Acceleration for Jupyter Cells

In the realm of AI, data science, and machine learning, Jupyter Notebooks are highly valued for their interactive capabilities, enabling users to develop with immediate feedback and iterative experimentation.
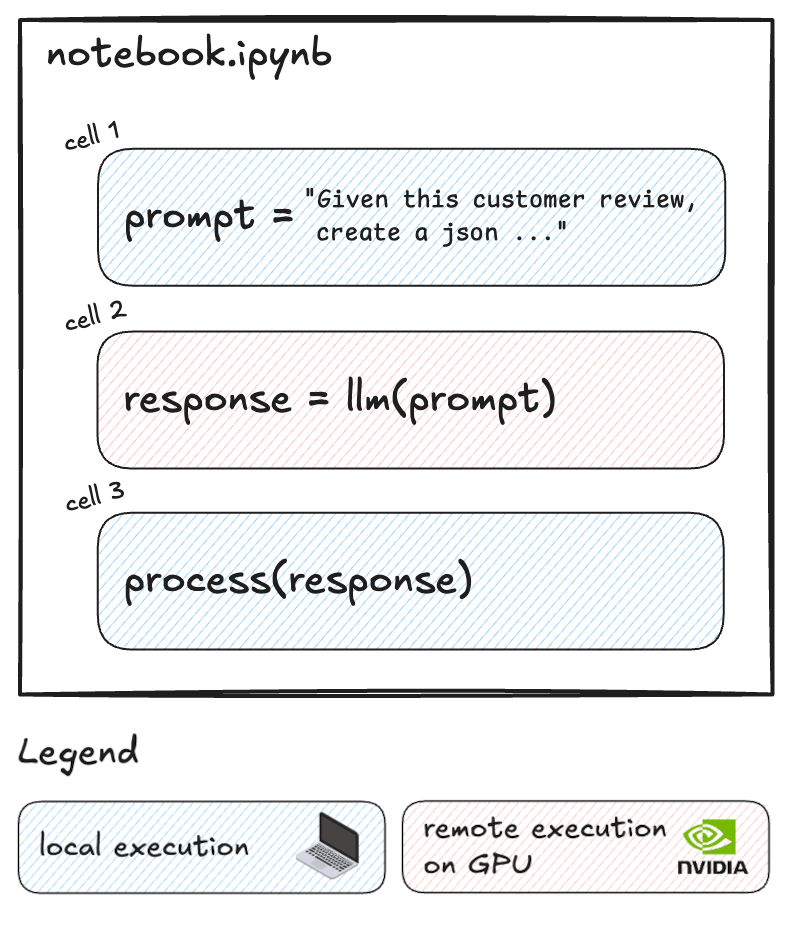
However, as models grow in complexity and datasets expand, the need for powerful computational resources becomes critical. Traditional setups often require significant adjustments or sacrifices, such as migrating code to different platforms or dealing with cumbersome configurations to access GPUs. Additionally, often only a small portion of the code requires GPU acceleration, while the rest can run efficiently on local resources.
What if you could selectively run resource-intensive cells on powerful remote GPUs while keeping the rest of your workflow local?
That's exactly what Datalayer Cell Kernels feature enables. Datalayer works as an extension of the Jupyter ecosystem. With this innovative approach, you can optimize your cost without disrupting your established processes.
We're excited to show you how it works.