Persistent Storage and Datasets


When working with Remote Kernels, one of the key pain points for users has been the lack of persistent data storage. Previously, every time you initiated a new kernel session, you would lose access to your previous data, forcing you to download datasets repeatedly for each new session. This not only wasted valuable time but also made the workflow cumbersome.
Persistent User Storage
The good news? We've introduced a solution that completely eliminates this problem! Now, you can persist data on the kernel side, meaning your data is saved even when your kernel is terminated. No more re-downloading files for every new kernel – your data is always available, just like it would be in your home folder on your own machine.

This is a massive time-saver and enhances productivity, allowing you to focus on what really matters: building models, analyzing data, and running experiments without constantly managing your data files.
A Smoother User Experience
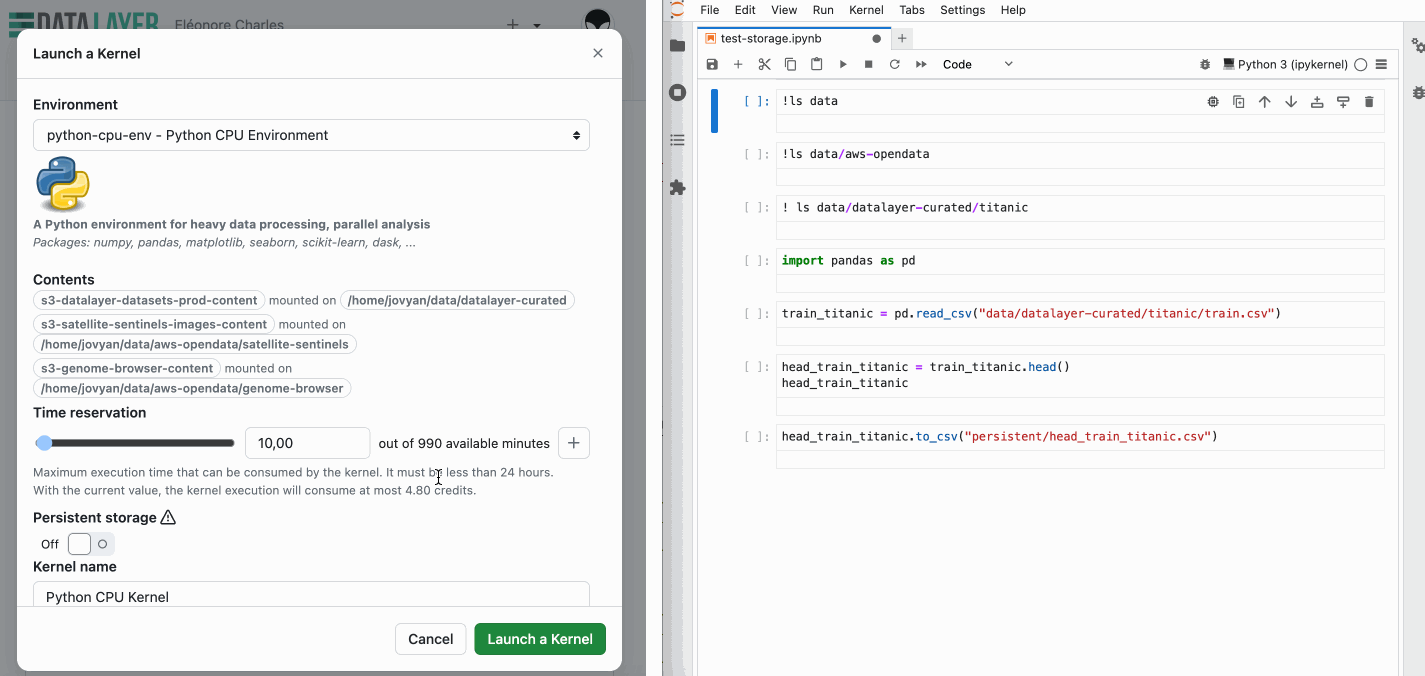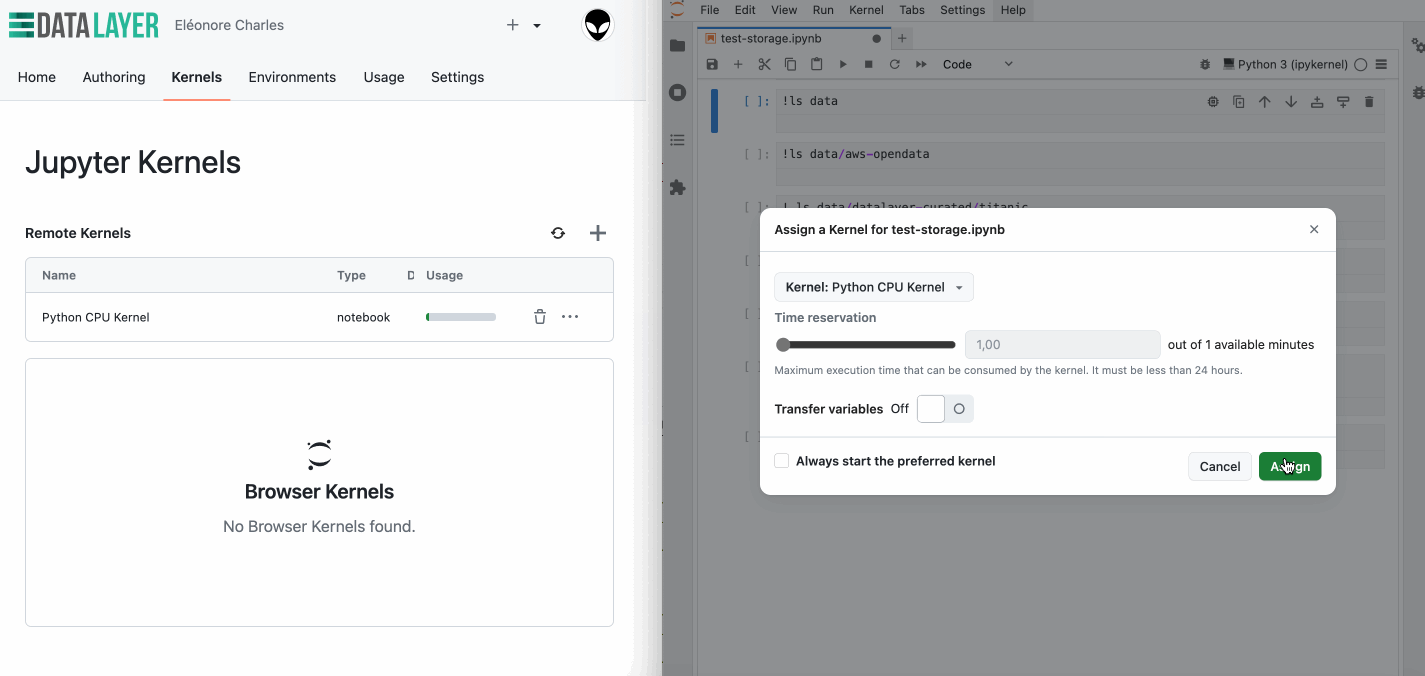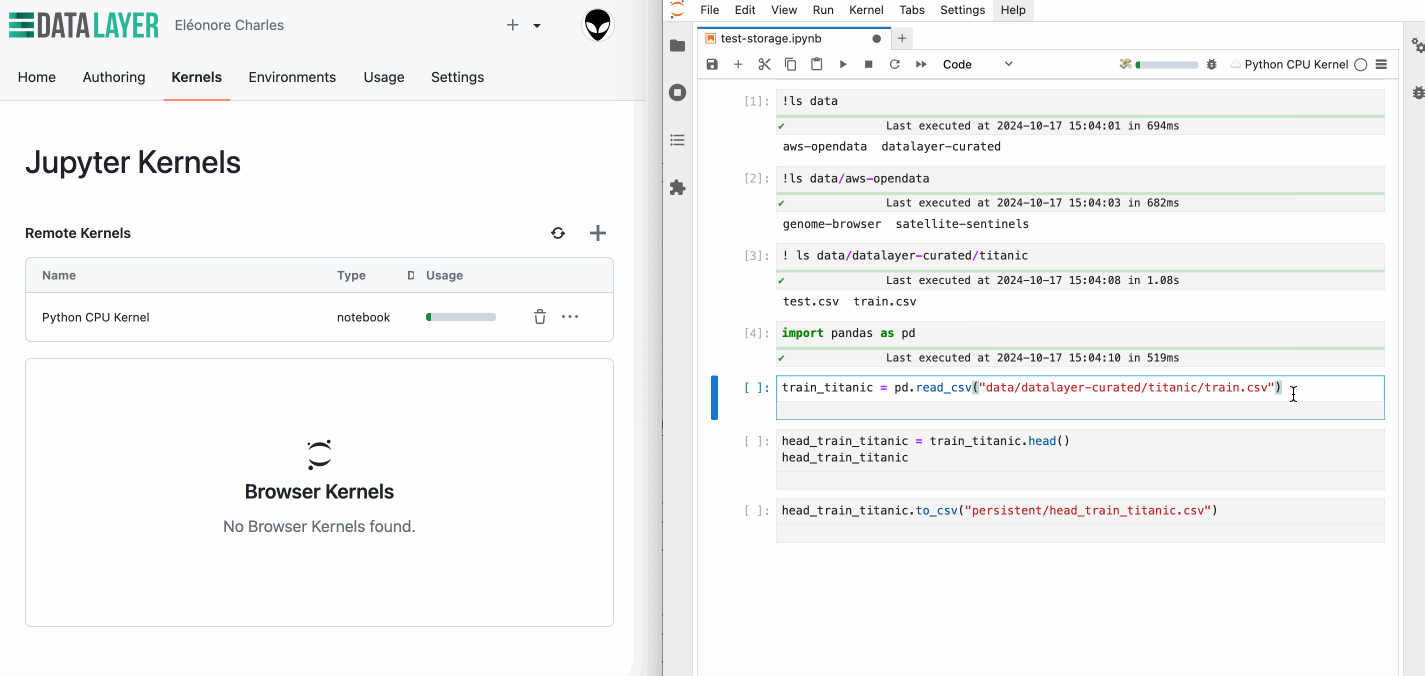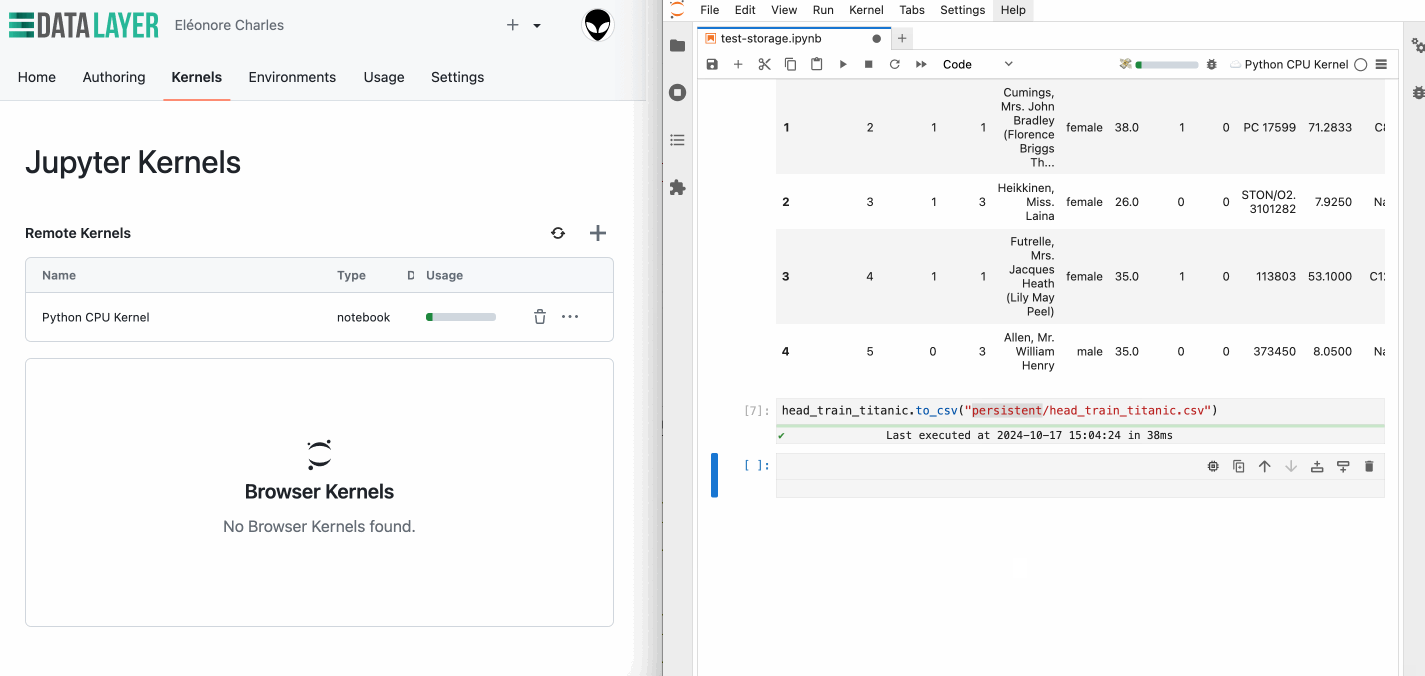
So, what does this look like in practice? When launching a new kernel, you have the option to enable persistent storage. Once enabled, the system automatically mounts a persistent storage in the persistent directory. This directory is accessible across different kernel sessions, ensuring that your data remains intact and available anytime you need it.
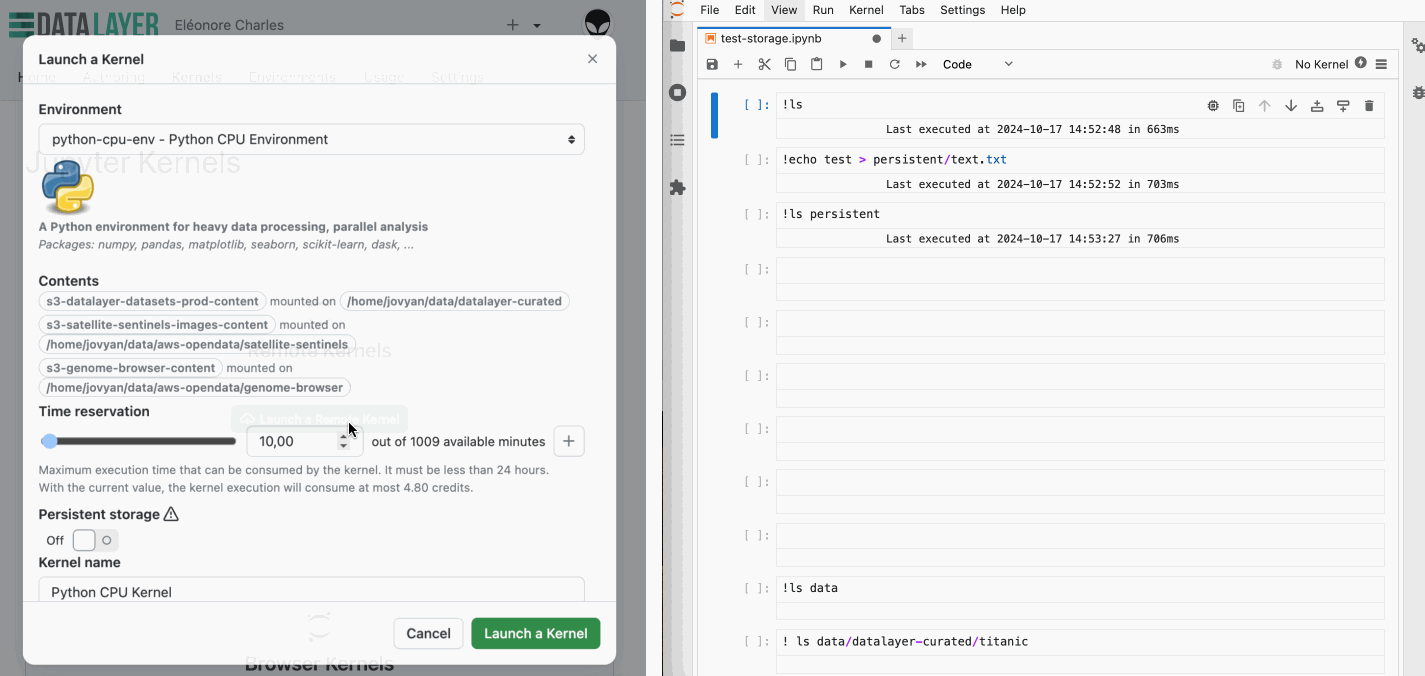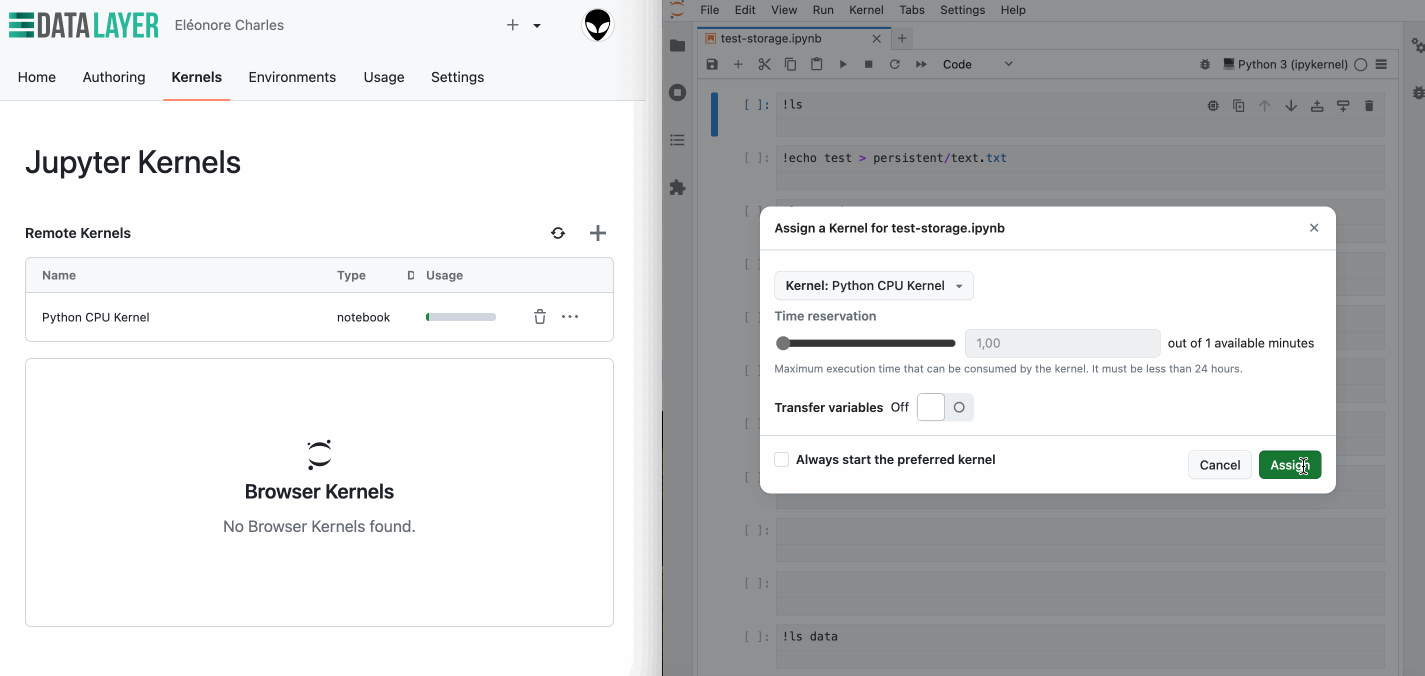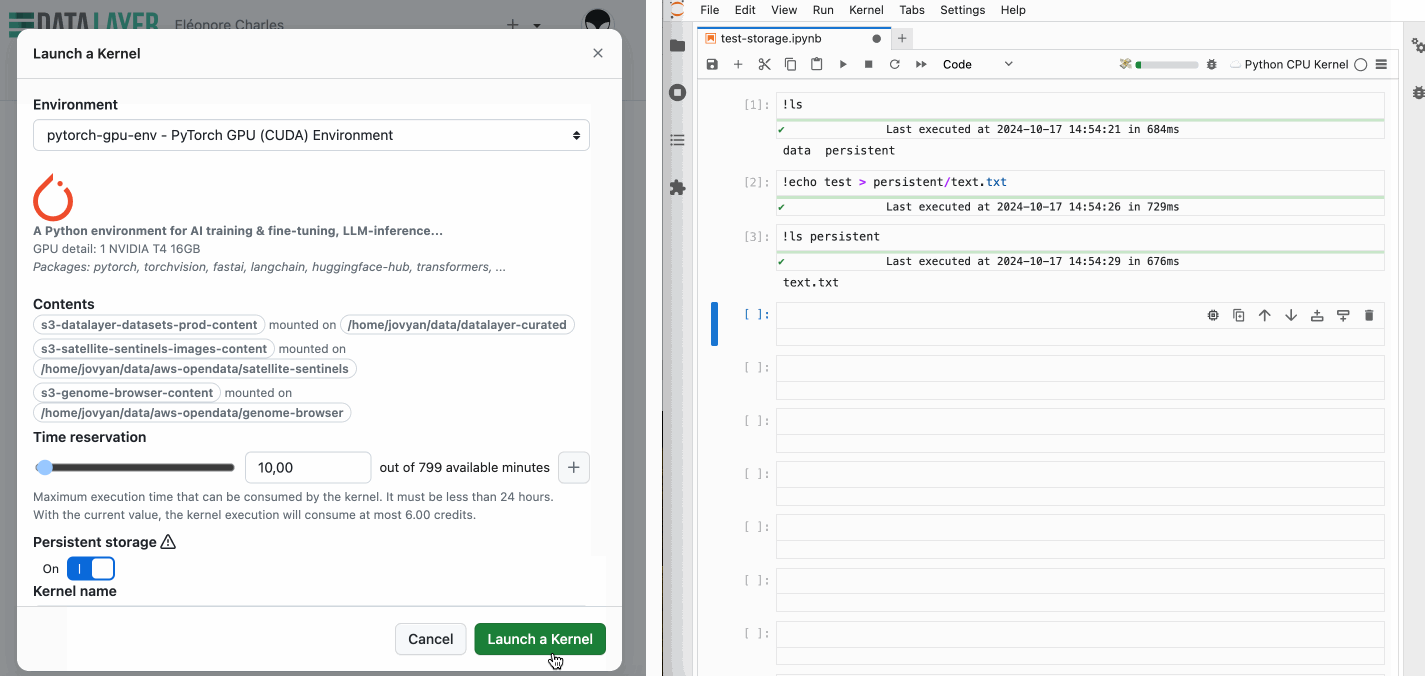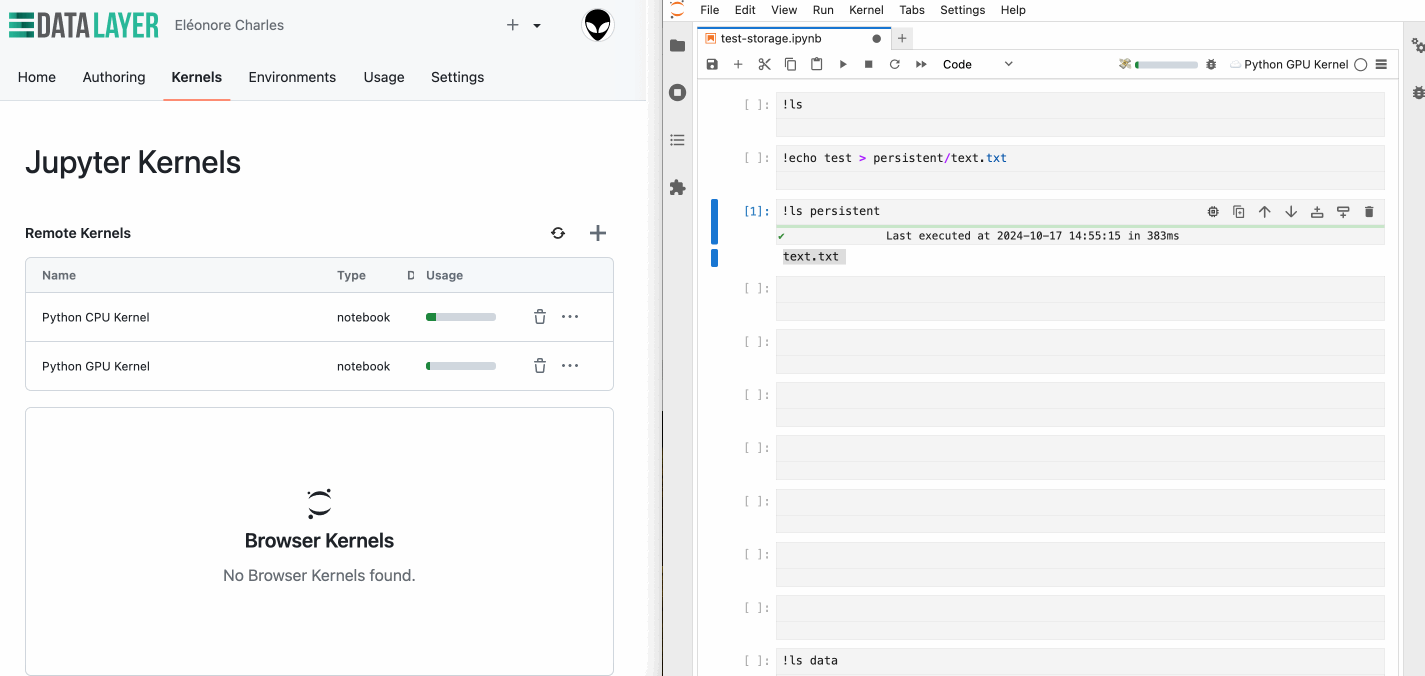
While enabling persistent storage slightly increase the kernel start time, the convenience of having your data ready across sessions might far outweighs this.
If you were using Datalayer with JupyterLab or CLI, you can upgrade the extension to get this feature available using the following command: pip install datalayer --upgrade
How Does It Work Under the Hood?
Building reliable, persistent storage for cloud environments requires robust infrastructure. To achieve this, we've implemented the Ceph storage solution. Ceph is a highly scalable and reliable storage system commonly used by top cloud providers like OVHcloud. It is designed to handle large volumes of data while ensuring high availability, redundancy, and data protection.
To learn more about how we have implemented a Ceph storage in our platform, check out our technical documentation: Ceph Service and User Persistent Storage.
Pre-Loaded Datasets
In addition to persistent storage, we've introduced a dedicated directory, data, where you can access a collection of pre-loaded datasets. This feature allows you to jump straight into your analysis without needing to upload your own data, making it easier and faster to get started.
The directory is set to read-only, so while you won't be able to write directly to it, you can effortlessly copy datasets over to your persistent storage for further modification. You'll find a range of popular datasets in the datalayer-curated subdirectory, including the classic Iris dataset, the Titanic dataset, and many more.
Several Amazon Open Data datasets are also available in the aws-opendata subdirectory, providing a wealth of data for your analysis.
What's Next?
We're not stopping here. There are several exciting enhancements on our roadmap, designed to further improve your experience:
- Expanded Storage Capabilities: We plan to increase storage limits, allowing you to store even more data.
- Storage Browsing: A new feature that will allow you to browse your kernel's content directly within JupyterLab and Datalayer platform.
- Storage Management: You'll soon be able to view and manage your storage directly from JupyerLab and Datalayer platform (delete, move, rename files with a user interface instead of using terminal command).
- Sharing Content Between Users: We are working on a feature that will enable you to share persistent data with other users, facilitating collaboration on projects.
Stay tuned for these upcoming features, as they will further enhance your ability to analyse data efficiently with Remote Kernels!
Refer to our documentation for more information on how to get started with persistent storage and pre-loaded datasets.
