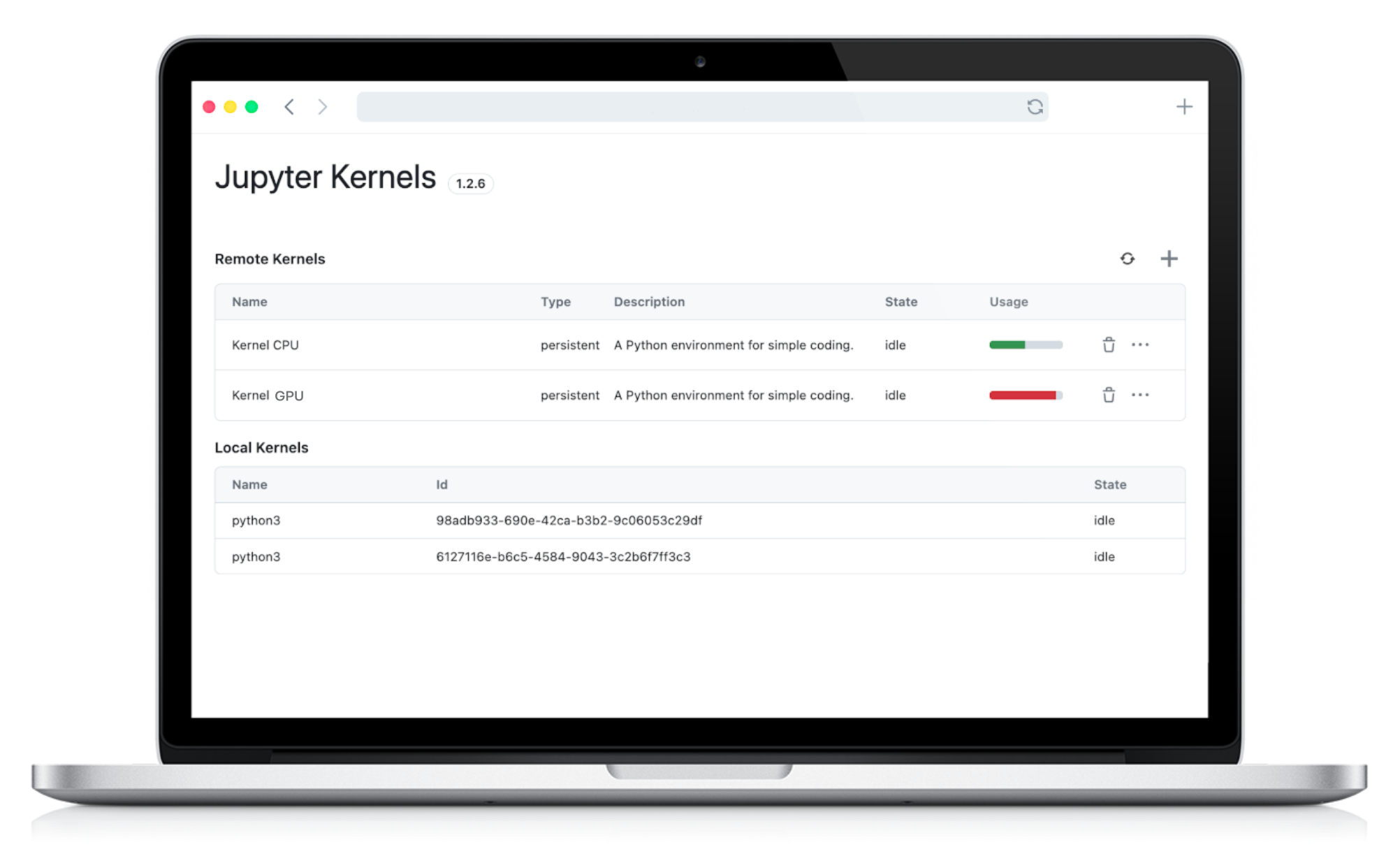
Persistent Storage and Datasets
· 5 min read


When working with Remote Kernels, one of the key pain points for users has been the lack of persistent data storage. Previously, every time you initiated a new kernel session, you would lose access to your previous data, forcing you to download datasets repeatedly for each new session. This not only wasted valuable time but also made the workflow cumbersome.