Towards a cloud native Jupyter

All Data Scientists know that story... Install the well-known Jupyter Classic or JupyterLab Notebook on their local PC/laptop, pip install some python libraries like pandas..., download some datasets and finally start analysing with a notebook in isolation. There are a few pain points there:
- Setting up the tools is hard and time consuming. You have to install Python, Jupyter and add the libraries you need. Conda environments or Docker containers can help mitigate the pain at some point, but finally these are yet additional tools to setup and manage.
- At some point, they want to collaborate with teammates, or want to share some results. The Data Scientist is just on his island and has no easy way to break the silo. The recent Realtime collaboration features have been merged into JupyterLab but it is just the permises and miss fundamental building blocks like identity, authorization...
- The analysis is not easily reproducible. The setup you have done on a particular Windows platform is completely different from the setup another collaborator may have done on macOS.
More Cloud-native
There comes the need for an better solution. At Datalayer we think that a more Cloud-native Jupyter can help remove those pain points. In other words, we embrasse the infrastructure provided by cloud providers like GCloud, AWS, Azure... and build on top to provide more power to the Data Scientist.
Cloud native computing is an approach in software development that utilizes cloud computing to "build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds.
Wikipedia https://en.wikipedia.org/wiki/Cloud_native_computing
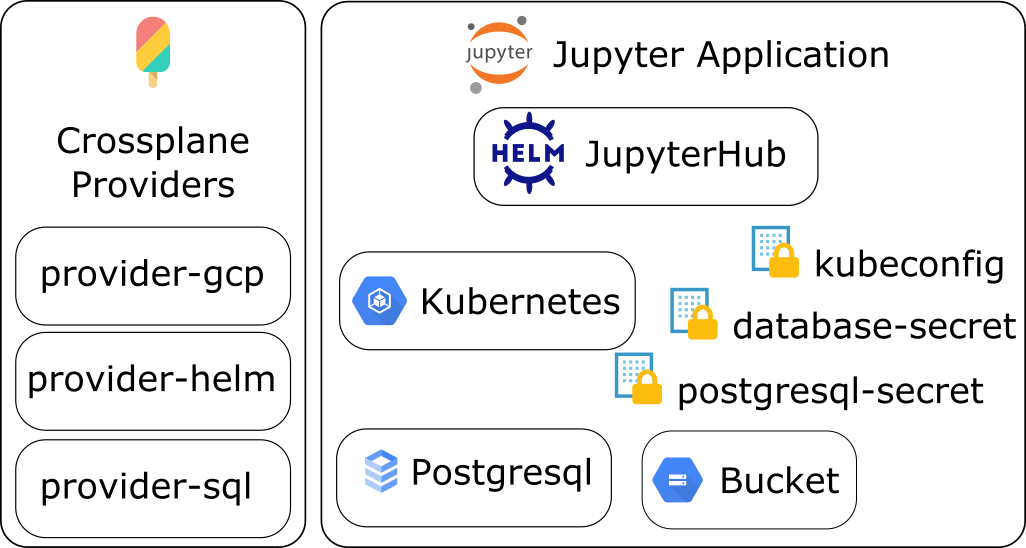
To move towards that goal, we have started building a Jupyter Showcase with Crossplane, a one-click solution to instanciate the needed infrastructures and application services described on the below diagram: JupyterHub, Kubernetes Cluster, SQL Database and Storage Bucket are all created for you giving just a few parameters, like e.g. the number of nodes for the Kubernetes cluster.
And if you don't want to provide any parameters, that's fine, we have defaults for you.
Once you have Crossplane installed on your Kuberntes cluster, there is just 2 steps to complete.
# 1. The Cloud Administrator deploys the platform definition.
kubectl create -f ./platform
# 2. The Jupyter Administrator create the platform with a claim.
kubectl create -f ./example/claim
Easy, as a Jupyter Administrator, you get a platform with a single command.
Credentials injection
We are using the zero-to-jupyterhub-k8s helm chart, and we make it easier for you to use this chart with e.g. the injection of credentials that Crossplane configurations offers.
The credentials of the SQL Postgresql database if first created by the provider-gcp, the provider responsible to create the infrastructure on Google cloud. Then those credentials can be reused by the provider-sql to create in the JupyterHub database the needed schemas and roles.
All those secrets can be used by the JupyterHub Helm chart. As a Cloud Administrator, you have access to them, but don't have to provide any if you don't want to!
A few technical issues...
We have been happy to get support from the open source Crossplane community on Slack and on the GitHub issues to get this working. At first glance, this is not easy to understand, but once you get the trick, it shows to be very powerfull and flexible. We'd like to report here two specific issues we worked-around while developing this solution.
The first issue we have encountered was about the population of the hub database url, the hub.db.url value of the Helm chart. That value is supposed to contain a combination of the IP address, username and password available in a Kubernetes secret. However, Crossplane V1.2.0 was not providing the CombineFrom field, which is now available in v1.3.0, see details on issue crossplane/#2353. To workaround that limit, we have modified the official Helm chart with our own version. This will be reviewed now that Crossplane v1.3.0 has been released.
The second issue we have been facing is about the version of Helm Golang library required by the Helm chart which was not met by the Crossplane provider-helm. This issue is still open, see provider-helm/#93, so we do not use for now the latest version of the Helm chart.
Next steps
There is room for improvement with more features
The Jupyter platform is accessible via a simple IP address. We should use the DNS service to create a hostname resolution to that IP address. We should also ensure SSL, potentially asking the cloud to provide a certificate. It is available today for Google Cloud and should be later expanded to Amazon Web Services as to Microsoft Azure.
