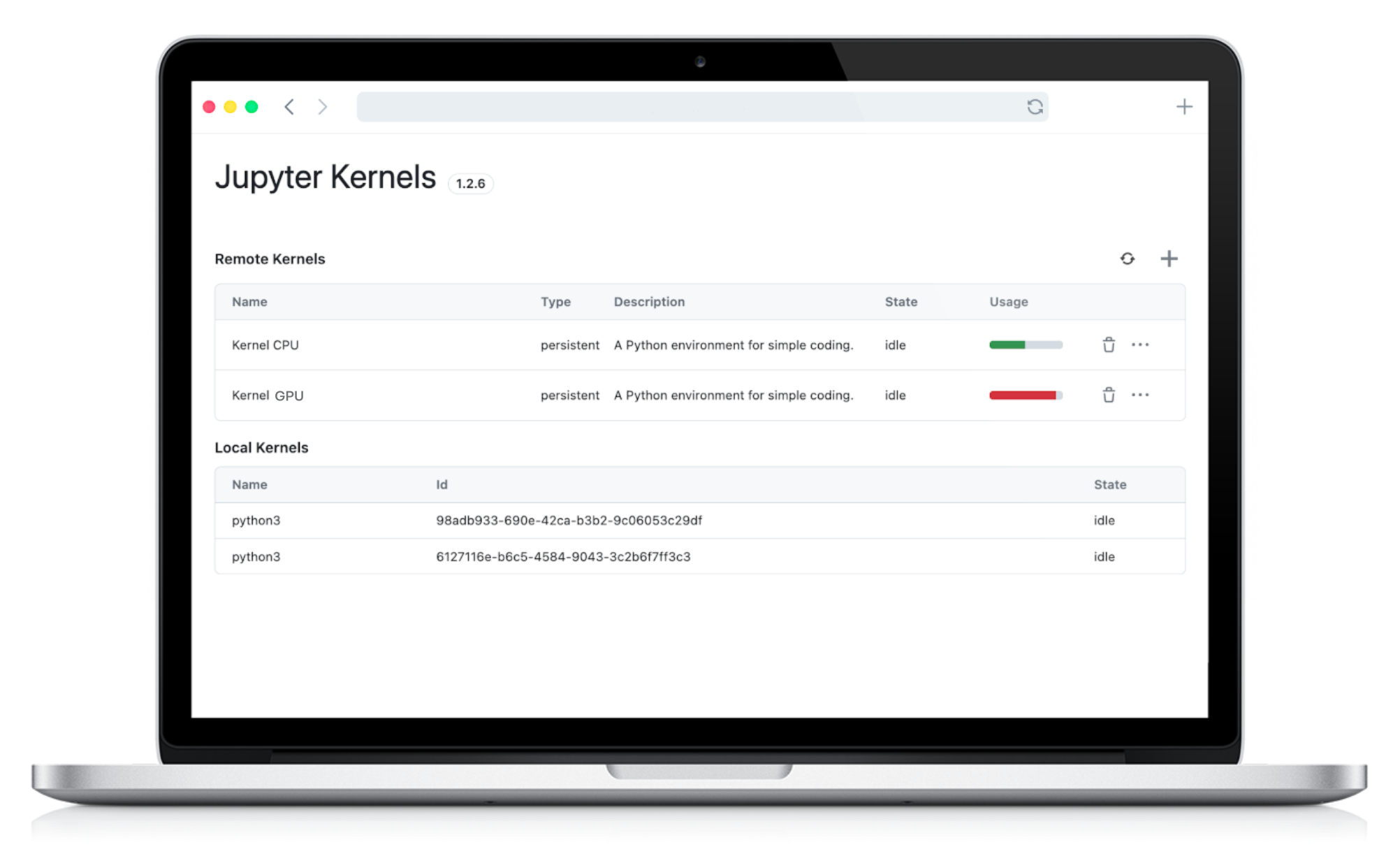
Working with Jupyter notebooks has long been a go-to for data scientists, developers, and researchers. But if you've ever had to terminate a Kernel and lost all your variables and notebook state, you know the frustration that comes with starting from scratch.
Until now, there was no easy way to keep your progress intact while managing resource consumption efficiently. A typical way to avoid rerunning all the cells was to save your variables to a file. However, this additional step could be time-consuming and disrupt your workflow.